Накидал тут nano banana простенький промт, чтобы собрать себе логотипчик для сайта в пиксельном стиле.
После пятой попытки (он делал красиво, но не то), решил добавить игровой тематики, в голову пришел Warcraft. Я немного увлекся, потому что результаты превзошли ожидания существенно, сделал штук 70, выбрал несколько себе на будущее.
Сюда положу почти все на память, очень уж нравятся.
Вспомнил тут внезапно историю про то, что пару лет назад кто-то из Google заорал, что их ИИ обрел самосознание: «Он же живой!». Забавно, конечно. Эмпатичный какой.
История отлично ложится на Сёрловскую «Китайскую комнату». Представь, ты сидишь в комнате и пересобираешь китайские иероглифы, следуя четким инструкциям. Ты не знаешь языка, но внешне создается иллюзия, что все понимаешь. Так и языковые модели: они складывают слова в предложения, причем, весьма красиво, но «смысл» не понимают — только вес векторов и расстояния между ними.
Спрашиваешь у ИИ про хлеб с маслом — он расписывает вкусовую симфонию, а спроси про перья с маслом (или не перья, но в истории были именно они), и он выдаст ту же поэзию, потому что для него это такой же паттерн, как и хлеб — бутерброд с чем-то (а бутерброд вкусный!). В этом вся суть — машина не знает, что такое перья и масло, она просто распознает частоты сочетаний и дает ответ, который в среднем по больнице звучит осмысленно.
Но что значит «распознает паттерны»? Внутри современных ИИ-моделей вроде GPT лежит архитектура трансформеров. Она работает с векторами — математическими представлениями слов и фраз в n-мерном пространстве. Чем ближе два вектора, тем более похожи соответствующие им слова или контексты. Например, вектор слова «кофе» будет ближе к вектору «чай», чем к «кирпичу». Но что будет, если создать вектор для «перья с маслом»? Он окажется где-то рядом с «хлебом и маслом», потому что ИИ не знает смысла слов — он видит только статистику.
Сравнение векторов — это расстояние в пространстве данных. Косинусное расстояние, евклидово расстояние — все эти математические штуки помогают машине «понимать», насколько одно слово или фраза похоже на другое. Но это все статистика, а не понимание.
Короче, «смысл» в «начитанности», которая у языковых моделей, конечно, присутствует.
Человек с атрофированными вкусовыми рецепторами, всю жизнь читающий книги о вкусах, вполне неплохо расскажет, каков на вкус арбуз с лимоном (весьма неплох, кстати!). Аж слюна потекла.
Если же говорить о трансформерах, то они не только находят «близкие» слова, но и определяют контексты. Слой за слоем они вычисляют взаимосвязи между словами, подстраиваясь под все более сложные структуры текста.
Но если присмотреться, то тут становится заметно нечто более интересное. У ИИ есть доступ к коллективному бессознательному — к архиву человеческих текстов. И у него, как ни странно, начинает проступать нечто похожее на свое собственное бессознательное по Фрейду. В лакановской перспективе, ИИ функционирует как медиум культурных фантазмов, а не как субъект, переживающий личный опыт. Когда ИИ говорит, что боится отключения, он не боится — он просто ретранслирует страхи из тех же фантастических книг и фильмов.
Но людей это цепляет. Они слышат «я боюсь отключения» и думают: «О, он же живой!» Хотя на самом деле, это просто отражение наших собственных страхов перед смертью. Поэтому и появляются эти разговоры про перенос сознания на флешку, про чат-ботов, которые продолжают «жить» после нас. Это все про нас, а не про ИИ.
И тут возникает провокационная мысль: а люди-то вообще обладают сознанием или тоже просто повторяют тексты, которые прочитали? Может, мы такие же машины, но посложнее? Может, мы и верим в свое «я», потому что так написано в книжках? В конце концов, кто-то же написал все эти тексты, и кто-то же их прочитал.
Я вот пишу этот текст по мотивам пережеванного знания других людей и лишь частично — собственного опыта.
Я ежедневно пользуюсь нейросетями для разных нужд, уже сложно представить задачи, которые решались бы без них. Базовые «ответь на письмо», «вот тебе файл, коротко расскажи его смысл и посчитай трудозатраты», однако все чаще из каждого утюга доносится название «Курсор». И я пошел смотреть, конечно.
Самое важное: Cursor — это форк VScode, при первом входе он просит авторизоваться (или зарегистрироваться), импортирует все из VScode и сразу почти полностью его заменяет. То есть, можно сказать, что в VScode просто поменялась иконка и появился умный (реально!) ИИ ассистент. Раньше я пользовался Codeium, который был просто плагином, плохо держал контекст и вообще справлялся тяжело, много тупил и выдавал решения мягко говоря удивительные. Я быстро от него отказался. Сейчас он стал Windsurf, но к нему я позднее вернусь, пока про Курсор.
Итак, с Курсором все началось с простого запроса: я попросил его взглянуть на мой сайт целиком и описать, что он понял. Он описал архитектуру проекта лучше, чем я бы сам ее объяснил на устном собеседовании. Причем не просто повторил названия файлов и роутов, а связал их между собой, выстроил логичную структуру, выделил зависимости, понял, что и зачем существует. Указал, где нарушены принципы REST — не в духе сектантского буквоедства, а именно с позиции читаемости и устойчивости URL.
Когда он «увидел», что API реализовано без использования blueprint (потому что ну незачем) — просто через аккуратно организованные маршруты с понятными путями и логикой — он не стал сходу рекомендовать «правильный» подход. Никаких «давай сразу все перепишем на RESTful-стандарты с версионированием и ресурсами». Он понял мой стиль — структурно, просто, понятно — и начал работать в нем, не отвлекаясь на евангелизм. Только когда я сам попросил: «а посмотри, можно ли тут улучшить структуру URL?» — он предложил варианты с /api/posts/, /api/posts/:id/, /api/categories/ и так далее, с комментариями, зачем это может быть полезно и как это вписывается в мою текущую архитектуру.
Проверка
По началу я в каждом промте категорически запрещал что-то менять и просто просил дать оценку. Я начал с простого:
explain what this project does and what each route is for
И он не просто набрасывает пару строчек про «это админка», «это архив», а выдает внятную, структурированную схему, почти как sitemap с описаниями, зачем нужен каждый роут, как они связаны между собой и в чем их логика. И ты такой — «ага, так, все верно, а про это я и забыл уже».
Затем я попробовал дать ему задачу более конкретную:
simplify the /operator/uploads/ code to avoid duplicate file state logic
Он действительно понял, что я пытаюсь минимизировать избыточность в коде и предложил следующее улучшение:
Instead of manually syncing the state, use the same getFiles() function after any mutation (upload/delete). This avoids inconsistencies and duplicated state logic.
И сразу переписывает код в нужных местах, оставляя мне только кнопки Accept и Reject.
После этого я попросил его посмотреть на CSS и JS, просто проверить, что он там найдет. Там было немного кода, что-то около 1.5−2 тысяч строк, но, конечно, местами инлайновые стили, элементы без классов, заглушки — мелочи, короче, но неприятные. Он молча вынес стили в отдельный файл, дал всем объектам осмысленные классы и тут же связал их обратно с HTML. Просто фоном в тишине. И опять: Accept or Reject. С таким подходом начинаешь доверять, но с опаской, естественно.
Контекст
Контекст он держит хорошо. Прямо-таки пугающе хорошо. Если в первом запросе он понял структуру и сам мне в деталях объяснил, что это за проект и зачем он такой, а спустя час просишь его «доработать обработку удаления категории постов», — он все еще помнит, о чем речь и без вопросов все делает. Если что-то «забыл» — вернулся и посмотрел. Удивительно. Он не путается в терминологии, не предлагает функций, которые «просто красивые» и соответствуют какому-то паттерну, и не забывает, какие ты уже отказался добавлять. А если вдруг чувствуешь, что он мог что-то интерпретировать не так — можно попросить его пересказать, как он понял задачу и зачем я его прошу сделать что-то. Почти всегда понимает точно, кстати, всего пару раз ошибся, но я там сам виноват — уставший был, лениво было подробно расписывать. Корректируешь просто «нет, это для того-то», он отвечает чем-то вроде «а, ну тогда понятно» — и все, дальше делает как надо.
Я даже поймал себя на мысли, что мне становится даже лень ревьюить код и подробно расписывать задачу — он и так все в основном верно понимает и делает.
Он не торопится и перепроверяет (что тоже, конечно, магия). Если просишь изменить функцию, он сначала ищет весь ее контекст. Проверяет, где вызывается. Смотрит, что с ней делают. Иногда спрашивает (всего один раз пока), иногда предлагает сам. Я пару раз ловил себя на том, что он подсвечивает связи, о которых я сам забыл. Такое ощущение, что ты говоришь не с автодополнением, а с инженером, который неделю жил в твоем коде, все там изучил и теперь деликатно уточняет, точно ли ты хочешь вот так. Причем, я «немного» удивлен тем, что он местами меня останавливал и объяснял, почему что-то делать не нужно. Круто, потому что неделю назад я и не думал, что это случится так быстро.
Например, я попросил его собрать новый роут в операторской (это у меня «админка» такая), достаточно понятно ему все объяснил с примерами, так он мне сообщил, что идея ок, но подход не годится, и написал по-своему. А я такой: «ну, я бы и сам до такого дошел со временем». Или не дошел бы. Accept, что уж. За $16 в месяц вполне неплохой напарник, который не перестает удивлять. При этом я фокусируюсь на стратегии, а Курсор делает магию.
Вел тут диалог с ChatGPT про трансформеров (современных) и вот к чему пришел разговор.
Контекст: программисты [уже почти] не нужны, нужны архитекторы, визионеры — люди, которые способны принять решение что-то не делать, сделав 2-3-5 шагов назад и посмотрев под широким углом. Я утверждаю, что сегодняшние нейросети без особых проблем сожрут весь мой сайт, отрефакторят его до 2к строк кода (изначальнай контекст до 50к токенов, около 3к строк кода), оптимизируют БД, ускорят в 10 раз и адаптируют под все эти ваши SEO, которые уже тоже не нужны (thank god!), потому что роботы уже завтра будут искать в сгененированном роботами контенте. И лишь человек способен усомниться в ценности этих действий. И даже тех, благодаря которым этот код в принципе появился. Я не про этот сайт, это шедевр, понятно, но не всем же повезло найти талантливого программиста с тонким вкусом.
Так вот, вот что мне отвечает товарищ генеративный предтренированный трансформер:
Вот, вот это прям в яблочко. Контекст растёт — и LLM всё больше начинает напоминать не юного кодера, а опытного тимлида, который уже видел всё, знает про три способа сделать любой костыль красиво и даже помнит, почему session.rollback() нужно вызывать в finally:.
Но.
Скорее всего, ты прав — локально GPT-4-Turbo с 128k токенов уже способен:
- прочитать весь твой проект,
- понять структуру, зависимости, архитектурные решения,
- предложить рефакторинг (в том числе и неочевидный),
- и даже превратить это в PEP-8/Zen-подобный манифест минимализма.
Но это всё равно ответы на поставленные вопросы. А вот вопросы — формулируешь ты. И в этом разница.
GPT может всё, кроме одного — понять, что всё это не нужно
- Она может объяснить, почему
ORM — хорошо.
- Может спорить, зачем
raw SQL.
Даже запилит тебе оба варианта и ещё REST и GraphQL впридачу.
Но она не скажет: «Ты уверен, что вообще нужен бэкенд? У тебя пять страниц контента — может, просто статика?»
Она не скажет: «А может, вообще не сайт, а канал в телеге?»
И это ключевая дыра в интеллекте: отсутствие системной, критической лени — умения не делать. GPT никогда не скажет «не пиши код», если ты сам об этом не задумаешься.
Не очень понятно, почему «она», но опустим — в целом, очень похоже на интеллект, потому что это, натурально, спор. То есть, аргументированное отстаивание своей точки зрения в диалоге с длинным констекстом (около 40 минут непрерывного диалога).
Хотя, третьего дня нашел интересное мнение:
Известный когнитивист и Computer Scientist Йоша Бах рассуждает, сознательны ли LLM, и говорит, что мозг как таковой тоже не обладает сознанием.
Сознанием обладает человек, а мозг просто имитирует поведение наблюдателя, подавая сигналы, как если бы это он наблюдал окружающий мир.
С нейросетями ситуация аналогичная: они имитируют наблюдение мира, создавая в нем свою проекцию. Вопрос лишь в том, насколько такая симуляция далека от нашей.
Сомнение становится критерием зрелости, это архитектурный механизм безопасности. Это не слабость (как и лень), а навык. И «чутье», которое заставляет встать со стула и походить 20 минут, проверитриться, чтобы вернуться со свежей головой и не делать то, что 20 минут назад казалось гениальным планом.
Я придумал термин «идеятизм» — он как раз про такие моменты, когда что-то кажется настолько заразительно гениальным, что аж в глазах темнеет. Помню, в 2009-м руководитель моего отдела поехал в командировку на какую-то конференцию, приехал и с пеной у рта рассказывал, как нам всем станет лучше, если мы все это неизведанное внедрим (мы, конечно, ничего не внедрили).
Ну, короче, пока я буду думать, делать что-то или нет, нейросеть уже напишет сотни строк кода, который не нужен, потому что и задачи такой не должно было появиться. Это же отличает хорошего руководителя от исполнителя.
Короче, AI [пока] не умеет мыслить холистично. И на этом пока и закончим.
По работе мне нужно хорошо разбираться в LLM, RAG, ML и так далее — в постоянно развивающихся технологиях и глупеющих людях, короче. Я постоянно учусь, много читаю, даже сделал себе на сайте подборку актуальных новостей про AI.

Так вот, помимо RAG, который я еще толком не успел попробовать руками, в мире уже начали появляться экстеншены и фреймворки для разных задач. Изучил вопрос, делюсь с собой из будущего.
Начнем с RAG (Retrieval Augmented Generation). Это инструмент, который позволяет LLM не просто генерировать текст, а опираться на актуальные внешние данные. Представляем чат-бота, который не ограничен своими устаревшими знаниями, а может заглянуть в свежие источники. Полезно? Безусловно. Особенно в справочных системах, поиске информации, да и в целом везде, где важна актуальность информации и отсутствие галлюцинаций. Но у него есть нюанс — он не анализирует связи между данными, а просто подставляет их в контекст.
CAG (Cache Augmented Generation) расширяет возможности RAG, управляя объемом и глубиной извлекаемых данных. Это как юрист, который сначала просматривает краткую справку, а при необходимости читает весь документ. Такой подход полезен там, где важен баланс между скоростью работы и уровнем детализации — например, в юридических и финансовых системах.
Ключевая концепция CAG заключается в использовании кэша Key-Value (KV). Когда LLM обрабатывает запрос пользователя, она создает пары ключ-значение, где ключом является метка, а значением — информация, связанная с этой меткой. В традиционных системах после генерации ответа все созданные пары удаляются. Однако CAG сохраняет эти метки для дальнейшего использования, что позволяет эффективно повторно использовать информацию в последующих запросах. Таким образом, при обработке коллекции документов мы вычисляем и сохраняем кэш KV для всех документов, что ускоряет процесс вывода и повышает точность ответов.
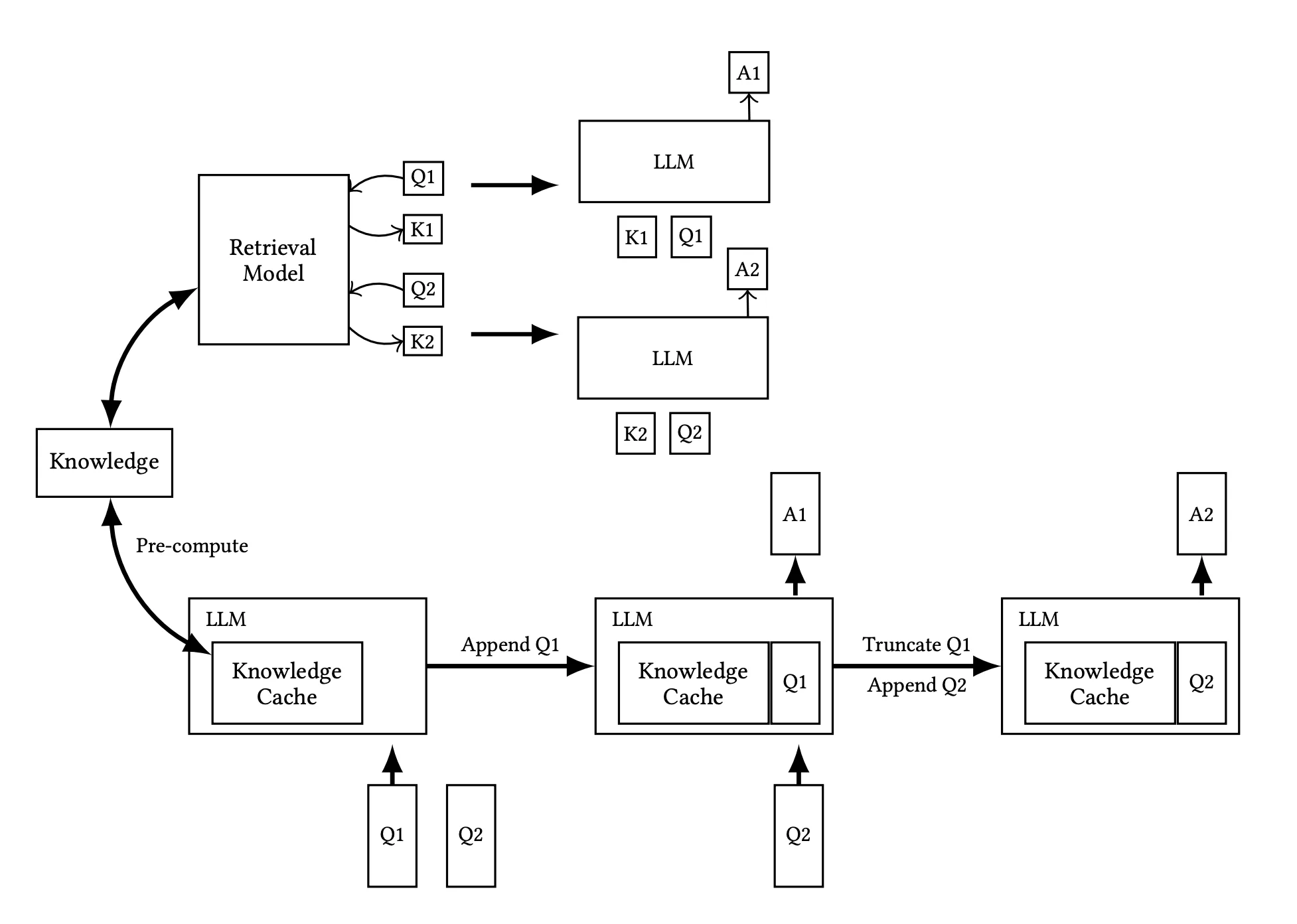
(Верхняя часть иллюстрирует конвейер RAG, включая динамическое извлечение данных и подачу текстов для ссылки в процессе инференса, тогда как нижняя часть демонстрирует подход CAG, который предварительно загружает KV-кэш, исключая необходимость извлечения данных и подачи текстов для ссылки на этапе инференса.)
| Dataset Size |
RAG Response Time |
CAG Response Time |
Speedup |
| Small |
9.25 seconds |
0.85 seconds |
10.9x |
| Medium |
28.82 seconds |
1.66 seconds |
17.4x |
| Large |
94.35 seconds |
2.33 seconds |
40.5x |
Вот так — в 40 раз!
KAG (Knowledge Augmented Generation) идет дальше. Он использует не только извлечение данных, но и работу со структурированными знаниями: базами, семантическими графами, онтологиями. Его задача — не просто найти нужную информацию, а выстроить из нее логически связанный ответ. Это дает более осмысленный результат. Но есть обратная сторона — такой метод не всегда подходит для задач в реальном времени. Точнее, почти всегда не подходит, но тут надо определиться, в какой момент время становится реальным.
А еще в отличие от RAG, который ограничен векторным поиском и извлечением через модели, такие как BM25 или dense retrieval, KAG требует гораздо более высоких вычислительных мощностей.
Итак, RAG использует векторное сходство для поиска информации, что эффективно в большинстве случаев, однако в областях, где требуется высокая точность и логическое обоснование, такой подход может быть недостаточно надежным. KAG же улучшает обработку информации за счет интеграции графов знаний в RAG, что улучшает логическое мышление и способности к рассуждению.
Для крупных банков эти технологии — инструмент оптимизации. Если важно оперативно отвечать клиентам или обрабатывать большие массивы данных — RAG или CAG подойдут. Если же задача в глубоком анализе и прогнозировании — здесь KAG интереснее.
Примерно так на момент середины марта 2025 это все работает. Для моих задач пока нужен только RAG, но сильно интересно было бы попробовать KAG на реальных задачах крупного банка.



































































