I'm sorry, how exactly this generation is augmented?
По работе мне нужно хорошо разбираться в LLM, RAG, ML и так далее — в постоянно развивающихся технологиях и глупеющих людях, короче. Я постоянно учусь, много читаю, даже сделал себе на сайте подборку актуальных новостей про AI.

Так вот, помимо RAG, который я еще толком не успел попробовать руками, в мире уже начали появляться экстеншены и фреймворки для разных задач. Изучил вопрос, делюсь с собой из будущего.
Начнем с RAG (Retrieval Augmented Generation). Это инструмент, который позволяет LLM не просто генерировать текст, а опираться на актуальные внешние данные. Представляем чат-бота, который не ограничен своими устаревшими знаниями, а может заглянуть в свежие источники. Полезно? Безусловно. Особенно в справочных системах, поиске информации, да и в целом везде, где важна актуальность информации и отсутствие галлюцинаций. Но у него есть нюанс — он не анализирует связи между данными, а просто подставляет их в контекст.
CAG (Cache Augmented Generation) расширяет возможности RAG, управляя объемом и глубиной извлекаемых данных. Это как юрист, который сначала просматривает краткую справку, а при необходимости читает весь документ. Такой подход полезен там, где важен баланс между скоростью работы и уровнем детализации — например, в юридических и финансовых системах.
Ключевая концепция CAG заключается в использовании кэша Key-Value (KV). Когда LLM обрабатывает запрос пользователя, она создает пары ключ-значение, где ключом является метка, а значением — информация, связанная с этой меткой. В традиционных системах после генерации ответа все созданные пары удаляются. Однако CAG сохраняет эти метки для дальнейшего использования, что позволяет эффективно повторно использовать информацию в последующих запросах. Таким образом, при обработке коллекции документов мы вычисляем и сохраняем кэш KV для всех документов, что ускоряет процесс вывода и повышает точность ответов.
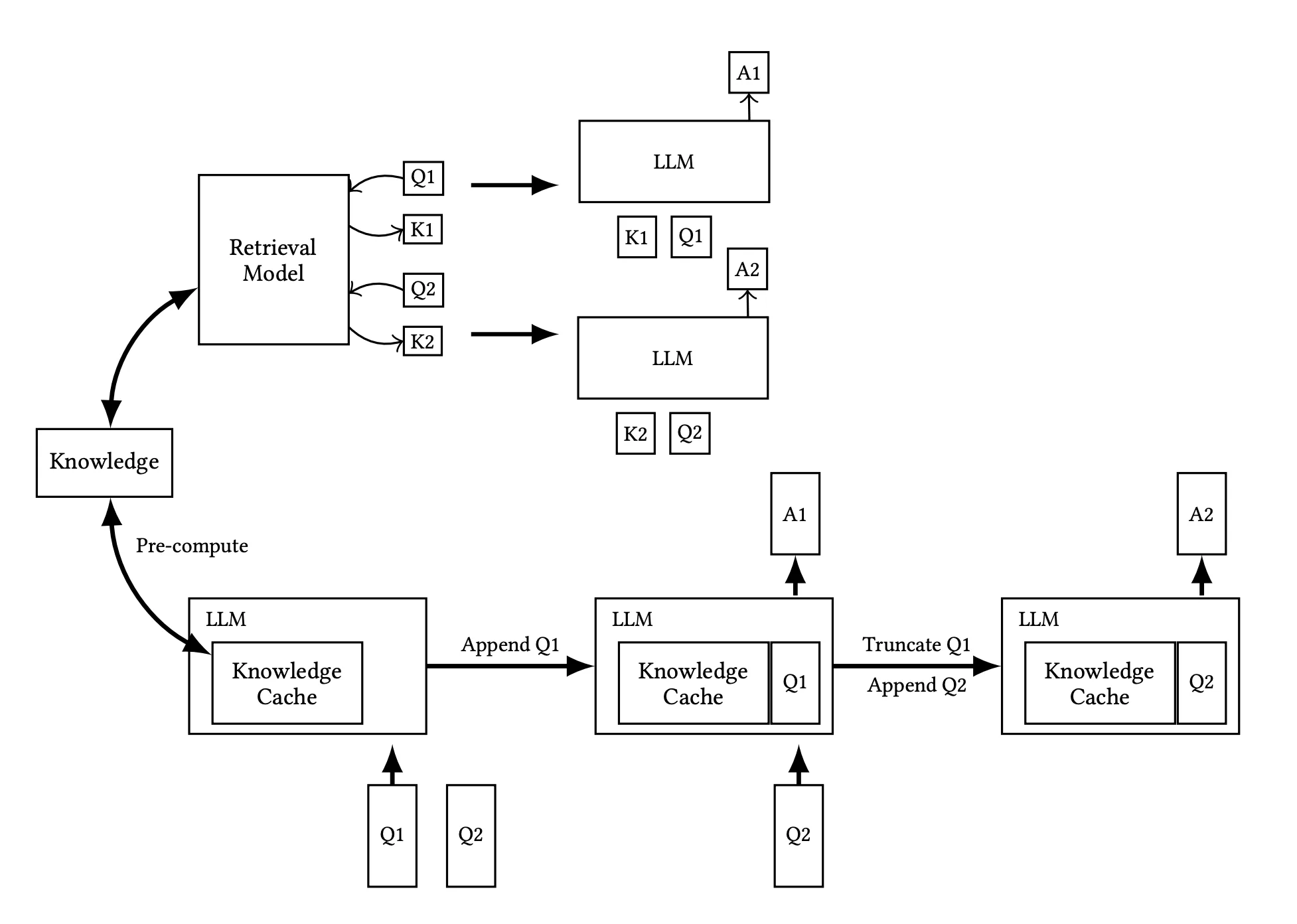
(Верхняя часть иллюстрирует конвейер RAG, включая динамическое извлечение данных и подачу текстов для ссылки в процессе инференса, тогда как нижняя часть демонстрирует подход CAG, который предварительно загружает KV-кэш, исключая необходимость извлечения данных и подачи текстов для ссылки на этапе инференса.)
| Dataset Size | RAG Response Time | CAG Response Time | Speedup |
|---|---|---|---|
| Small | 9.25 seconds | 0.85 seconds | 10.9x |
| Medium | 28.82 seconds | 1.66 seconds | 17.4x |
| Large | 94.35 seconds | 2.33 seconds | 40.5x |
Вот так — в 40 раз!
KAG (Knowledge Augmented Generation) идет дальше. Он использует не только извлечение данных, но и работу со структурированными знаниями: базами, семантическими графами, онтологиями. Его задача — не просто найти нужную информацию, а выстроить из нее логически связанный ответ. Это дает более осмысленный результат. Но есть обратная сторона — такой метод не всегда подходит для задач в реальном времени. Точнее, почти всегда не подходит, но тут надо определиться, в какой момент время становится реальным.
А еще в отличие от RAG, который ограничен векторным поиском и извлечением через модели, такие как BM25 или dense retrieval, KAG требует гораздо более высоких вычислительных мощностей.
Итак, RAG использует векторное сходство для поиска информации, что эффективно в большинстве случаев, однако в областях, где требуется высокая точность и логическое обоснование, такой подход может быть недостаточно надежным. KAG же улучшает обработку информации за счет интеграции графов знаний в RAG, что улучшает логическое мышление и способности к рассуждению.
Для крупных банков эти технологии — инструмент оптимизации. Если важно оперативно отвечать клиентам или обрабатывать большие массивы данных — RAG или CAG подойдут. Если же задача в глубоком анализе и прогнозировании — здесь KAG интереснее.
Примерно так на момент середины марта 2025 это все работает. Для моих задач пока нужен только RAG, но сильно интересно было бы попробовать KAG на реальных задачах крупного банка.